Node feature mapping for service clients
When
applying robust boundary and logic conditions to your service schema,
it is critical to understand how those rules are translated from the
WSDL to your client code.
Note that the BizTalk WCF Service Publishing Wizard is infinitely better than the classic BizTalk Web Services Publishing Wizard
when it comes to respecting the initial schema. Whereas the WCF wizard
keeps all schema properties intact after metadata publication, the ASMX
wizard removes occurrence limits, default values, and complex type
groupings.
Element grouping
Let's
first look at complex type grouping. When you erect a standard XSD
schema, by default, the schema expects all the XML nodes to be in the
sequential order set forth by the schema. However, you have options to
be more flexible than that. The question is though, how well do WCF
clients support a schema structure possessing such flexibility? We can
evaluate this by first setting up a Screen Result schema, which outlines the results of a physician screening of a drug trial subject. The original structure looks like this:
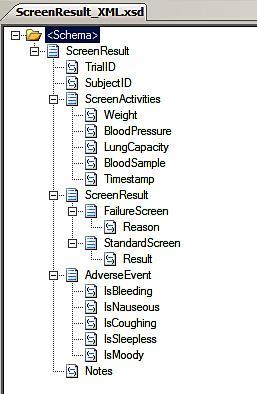
The ScreenActivites
record contains elements explaining a sequence of steps that must be
reported in a specific order. I can ensure this is the case by clicking
the ScreenActivities record, and setting the Context Type property equal to Complex Content. As soon as that value is set, a Sequence group is added to the ScreenActivites node.
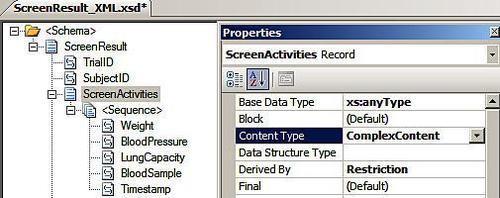
The second record of note, ScreenResult,
will contain either a "success" or "failure" node based on the
physician's evaluation of the screening visit. We want our schema to
expect only one of these two possible values. Once again, we can set the Context Type to Complex Content on this record, but this time, after the Sequence group shows up we should select it and flip the Order Type to Choice. This means that the schema expects one of the two records to be there.
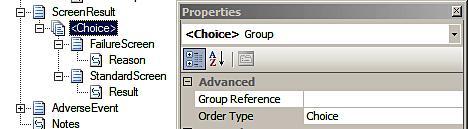
Finally, we have the AdverseEvent
record, which holds a list of Boolean values about possible side
effects we are keeping an eye out for. In this case, we can use an
alternate way to dictate the record behavior. After selecting the
record, and setting the Group Order Type to All,
I've told the schema that all these nodes need to be here, but, they
can exist in any order. One of the only real differences here is that
there is no visual indication of the record's grouping behavior. I'll
point out another difference in just a moment.
At
this point, we want to expose this schema as a WCF service so that we
can investigate how these grouping principles are (or aren't) applied
in the WCF client that consumes it. I created a very simple, one-way
WCF service (and metadata endpoint) using the Expose schemas as web service option of the BizTalk WCF Service Publishing Wizard.
After starting the generated receive location (so that the service is
enabled and browsable) I pointed my client application at the WSDL of
the service.
Investigating the generated .NET types reveals something curious. The object representing the ScreenActivities node is defined like this:
public partial class ScreenResultScreenActivities {
private string[] textField;
/// <remarks/>
[System.Xml.Serialization.XmlTextAttribute()]
public string[] Text {
get {
return this.textField;
}
}
It does not contain all the sub types (Weight, BloodPressure) that were child nodes in the schema. This is because the ScreenActivities node had its Sequence Content Type property. When we did this, the Base Data Type was automatically set to xs:anyType. Hence, the subsequent .NET class does not know about the actual contents of the ScreenActivities node. We can correct this by going back to our schema and removing the xs:anyType as the Base Data Type, and regenerating our WCF service endpoint. characteristic set by changing its
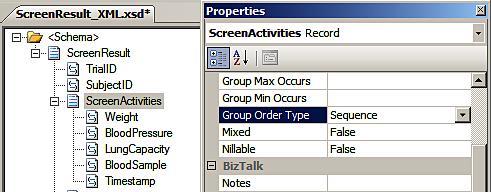
When setting the complex type grouping behavior, just set the Group Order Type property instead of changing the Content Type property. This will prevent serialization problems down the line.
How
does the generated .NET type class respect the schema grouping that we
defined? Notice in the code snippet below that for the sequence node, the corresponding class properties have order attributes in their serialization instruction. ScreenActivities
[XmlElementAttribute(Form=XmlSchemaForm.Unqualified, Order=0)]
public string Weight {
get {
return this.weightField;
}
}
[XmlElementAttribute(Form=XmlSchemaForm.Unqualified, Order=1)]
public string BloodPressure {
get {
return this.bloodPressureField;
}
}
What about the ScreenResult element that is has a choice grouping? In this case the ScreenResult .NET object has an Item property that will hold either the or StandardScreen objects. FailureScreen
[XmlElementAttribute("FailureScreen", typeof(FailureScreen)]
[XmlElementAttribute("StandardScreen", typeof(StandardScreen)]
public object Item {
get {
return this.itemField;
}
set {
this.itemField = value;
}
}
Finally, how is the concept of all XSD grouping handled by .NET client code? As you might expect, the code looks much like the sequence code, minus the mandatory node ordering attribute.
[XmlElementAttribute(Form= XmlSchemaForm.Unqualified)]
public bool IsBleeding {
get {
return this.isBleedingField;
}
set {
this.isBleedingField = value;
}
}
[XmlElementAttribute(Form= XmlSchemaForm.Unqualified)]
public bool IsNauseous {
get {
return this.isNauseousField;
}
set {
this.isNauseousField = value;
}
}
Overall then, XSD grouping clearly holds up pretty well when interpreted by WCF service clients.
Element properties
Next,
we need to confirm how element properties are mapped from XSD
definitions to .NET client code. Specifically, let's look at how
occurrence limits nullability and default values are handled. I've gone
ahead and modified our existing ScreenResult schema so that these new element properties are present. To do this I set:
The ScreenActivities node to have a minimum occurrence of 1, and a maximum occurrence of 5.
The Timestamp node, which is a xsd:dateTime, has its Nillable property set to True
The BloodSample default amount is set to Two Vials
The resulting XSD resembles this:

After rebuilding the WCF endpoint via the BizTalk WCF Service Publishing Wizard and then updating our client's service reference, we can see how these modified attributes are reflected. The ScreenActivities type does NOT capture the occurrence limits from the XSD, but does show a default value for BloodSample, and a type for the Timestamp property. nullable
public partial class ScreenResultScreenActivities {
private string weightField;
private string bloodPressureField;
private string lungCapacityField;
private string bloodSampleField;
private System.Nullable<System.DateTime> timestampField;
public ScreenResultScreenActivities() {
this.bloodSampleField = "2 Vials";
}
Keep
in mind that any well thought out limits on XML node occurrences won't
cascade down into the .NET clients that call your service.
Element restrictions
The last set of schema attributes to evaluate is restrictions placed on XML nodes. I've updated our existing ScreenResult schema by changing:
The failure screen reason will only accept an enumeration
The Notes field has a maximum field length of 150 characters
Added a regular expression pattern to the SubjectID field that looks for two letters and 5 numbers
All of these element restrictions are set by clicking on a schema node and changing the Derived By value to Restriction. This opens up an array of new attributes that can be applied to the selected node.

Once more, we can rebuild our BizTalk project, redeploy it, and rerun the BizTalk WCF Service Publishing Wizard.
As we would hope, the enumeration that existed in the schema node is
cleanly translated to a .NET enumeration type in the service client.
However, neither the field length restriction nor the regular
expression pattern flowed down to the generated .NET classes.
So
what can we glean from this investigation into node validation? While
.NET translates an impressive amount of XSD validation logic into its
service client objects, there are clearly gaps in the concepts that get
mapped across. This means that you should be cautious into building too
much data validation into your schemas if you expect your clients to
adhere to it. Also, going overboard and meticulously configuring each
schema node only makes later modification that much more difficult. For
instance, setting default values and adding enumerations are nice, but
what happens when a default value changes, or new enumeration choices
are needed? It may be better to actually avoid these types of tempting
restrictions in the spirit of abstraction and loosely coupling service
expectations from client requirements.